企业大模型选型指南:100位CIO总结的16条采购建议
生成式 AI 的落地分为两大场景,消费级与企业级。对于消费级 AI,我们可以通过 similarweb 等第三方网站获取其流量与用户使用情况;而对于企业级 AI,则需要参考专业的调研机构数据。
几个月前,知名投资机构 a16z 发布了一篇深度调研报告,通过一手访谈 20 多家企业级 AI 客户,以及 15 个行业的 100 位首席信息官(CIO),总结了 2025 年及未来企业如何使用、购买和规划新一代人工智能的 16 条建议。
AI 是一个快速变化的领域,今年的 AI 的市场结构已经比去年发生明显转变。这些趋势包括:
- 企业级 AI 预算超出了本已很高的预测,并从试点项目和创新基金升级为核心 IT 和业务部门预算中的经常性支出项目。
- 企业在混合搭配多种模型以在性能和成本之间进行优化方面变得更加成熟。OpenAI、Google 和 Anthropic 占据了总体的主导市场份额,而 Meta 和 Mistral 在开源选项中很受欢迎。
- 现在的 AI 采购跟传统软件购买方式很相似——包括更严格的评估、托管考虑和基准测试审查。而日益复杂的 AI 工作流程正在推高模型间的转换成本。
- AI 应用已经成熟:现成的(off-the-shelf)解决方案正在超越定制解决方案,并为 AI 原生的第三方应用程序带来回报。
以下是 16 条具体的企业级 AI 采购指南,将深入探讨在资源、模型、采购和应用使用方面的转变。
# 01
预算:AI支出远超高涨的预期并已成为常态
1. 预算超出预期且没有放缓迹象
LLM 预算的增长超出了企业一年前(本已很高的)预期,并且没有迹象表明这种增长会放缓。企业领导者预计未来一年平均增长约 75%。正如一位 CIO 指出的:“我在 2023 年的花费,现在一周就花完了。”
支出的增长部分是由企业发现了更多相关的内部用例和提高了员工采用率所驱动的。除此之外,我们开始看到更多面向客户的用例——尤其是对于技术前沿的公司——这些用例有可能推动支出呈指数级增长。一家大型科技公司表示:“我们到目前为止主要专注于内部用例,但今年我们专注于面向客户的生成式 AI,这方面的支出将会大得多。”
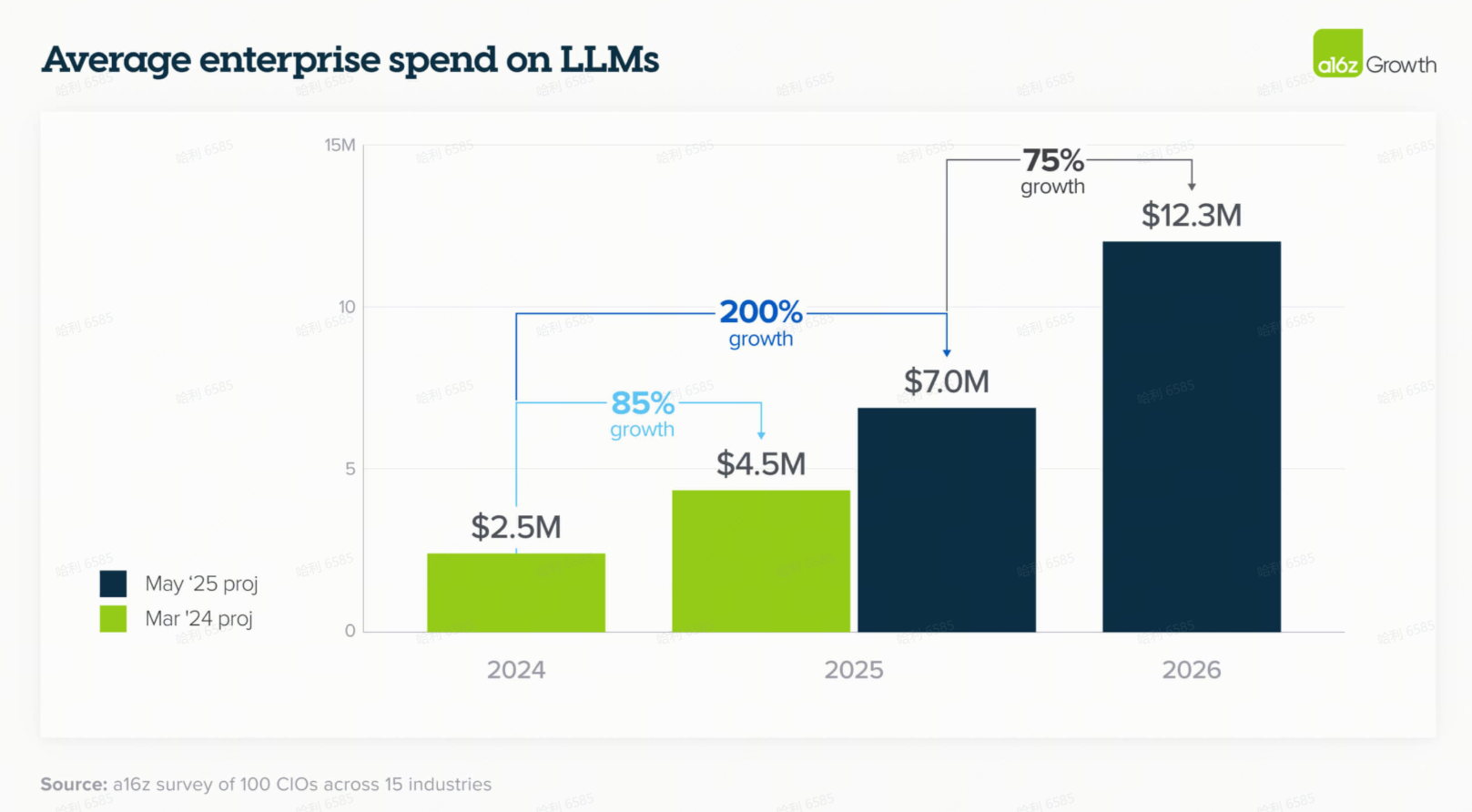
2. 生成式AI支出升级为永久性预算项目
去年,创新预算仍占 LLM 支出的四分之一,现在这一比例已降至仅 7%。企业越来越多地通过集中化的 IT 和业务部门预算来支付 AI 模型和应用程序的费用。这反映出一种日益增长的情绪,即生成式 AI 不再是实验性的,而是对业务运营至关重要。一位 CTO 指出:“我们更多的产品正在增加 AI 功能,因此我们的支出增长将在所有这些产品中上升”——这表明向核心预算的转变只会加速。

# 02
模型:三大领导者崭露头角,因用例性能差异化推动更多模型多样化
3.多模型时代已成定局,模型差异化——而非商品化——是关键驱动因素
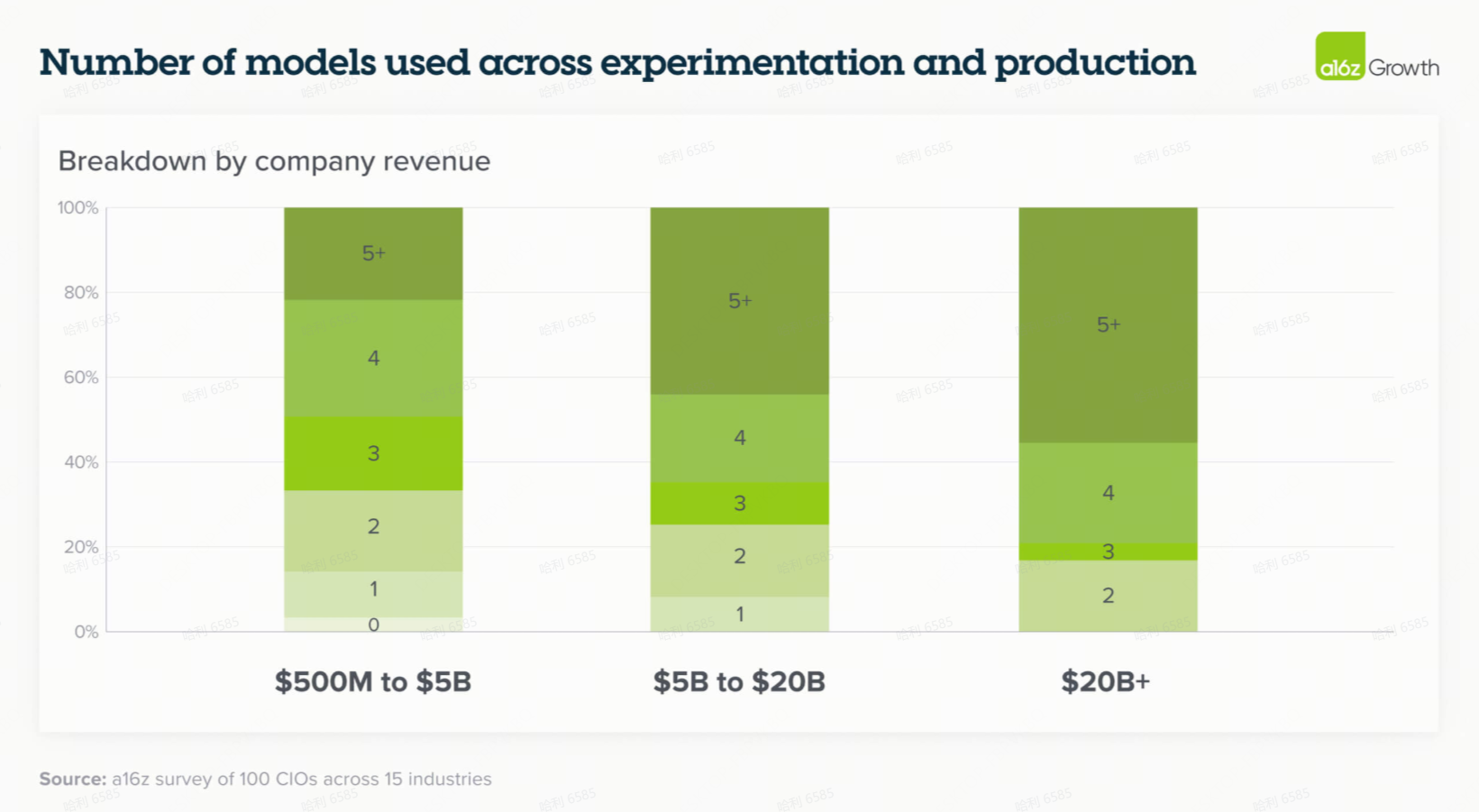
随着几个高性能 LLM 的问世,在生产用例中部署多个模型已成为常态。虽然这样做的原因之一肯定是为了避免供应商锁定,但按用例划分的模型差异化已变得越来越明显,并且成为企业从多个供应商购买模型的主要原因。在今年的调查中,37% 的受访者现在使用 5 个或更多模型,而去年这一比例为 29%。
虽然在某些情况下,模型在通用评估上似乎得分相当,但很明显,企业级模型层并未商品化。例如,Anthropic 的模型在编码相关任务中表现出色,但这种说法有更细微的差别。在编码领域内,一些用户报告称 Claude 在细粒度代码补全方面表现更好,而 Gemini 在更高级别的系统设计和架构方面更强。在其他领域,例如基于文本的应用,一位客户观察到“Anthropic 在写作任务上稍好一些——语言流畅性、内容生成、头脑风暴——而 OpenAI 模型更适合更复杂的问答。”
这些差异使得使用多个模型成为最佳实践,我们预计随着客户为追求性能而构建应用程序并关注保持供应商中立性,这一策略将继续下去。
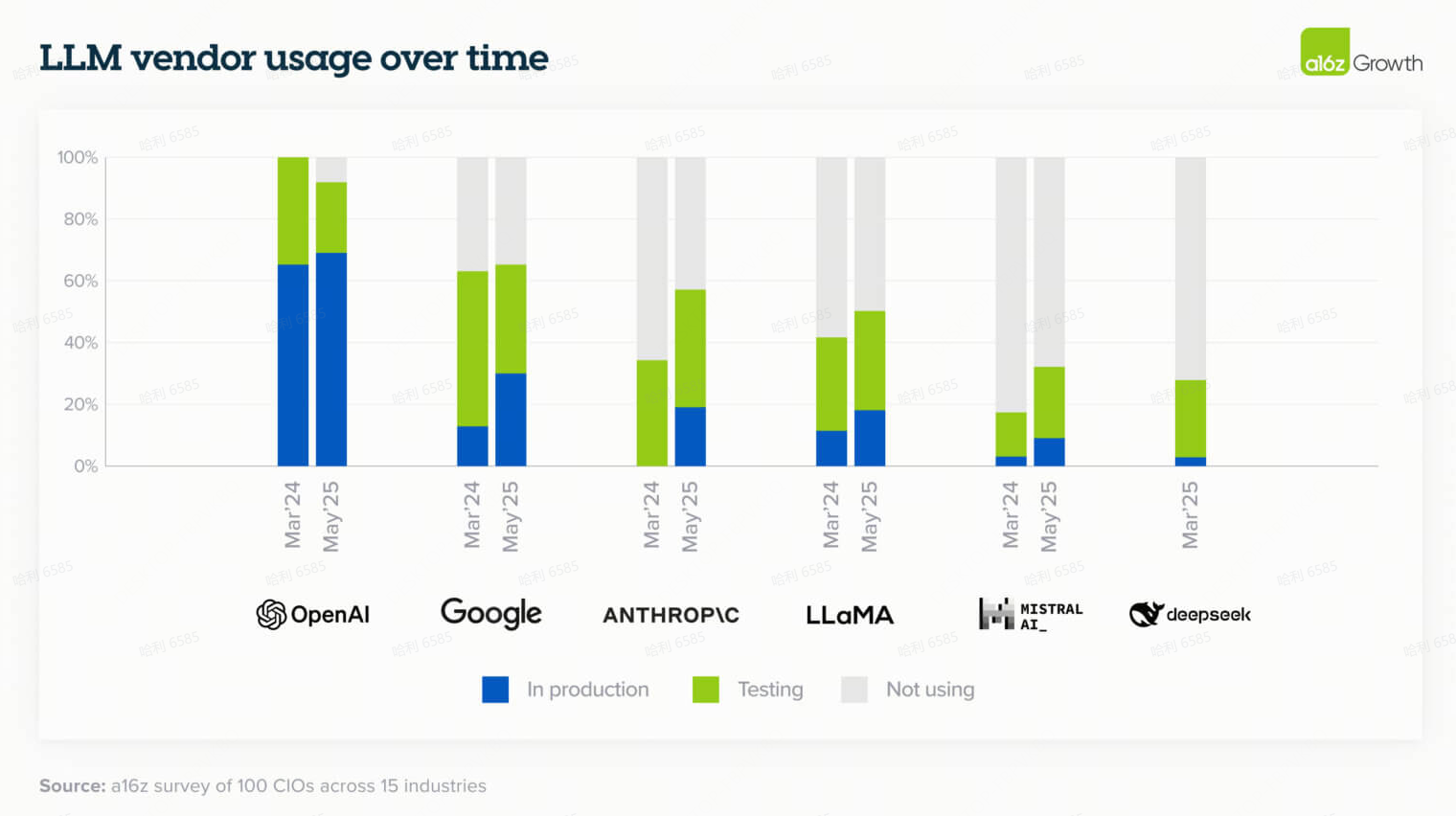
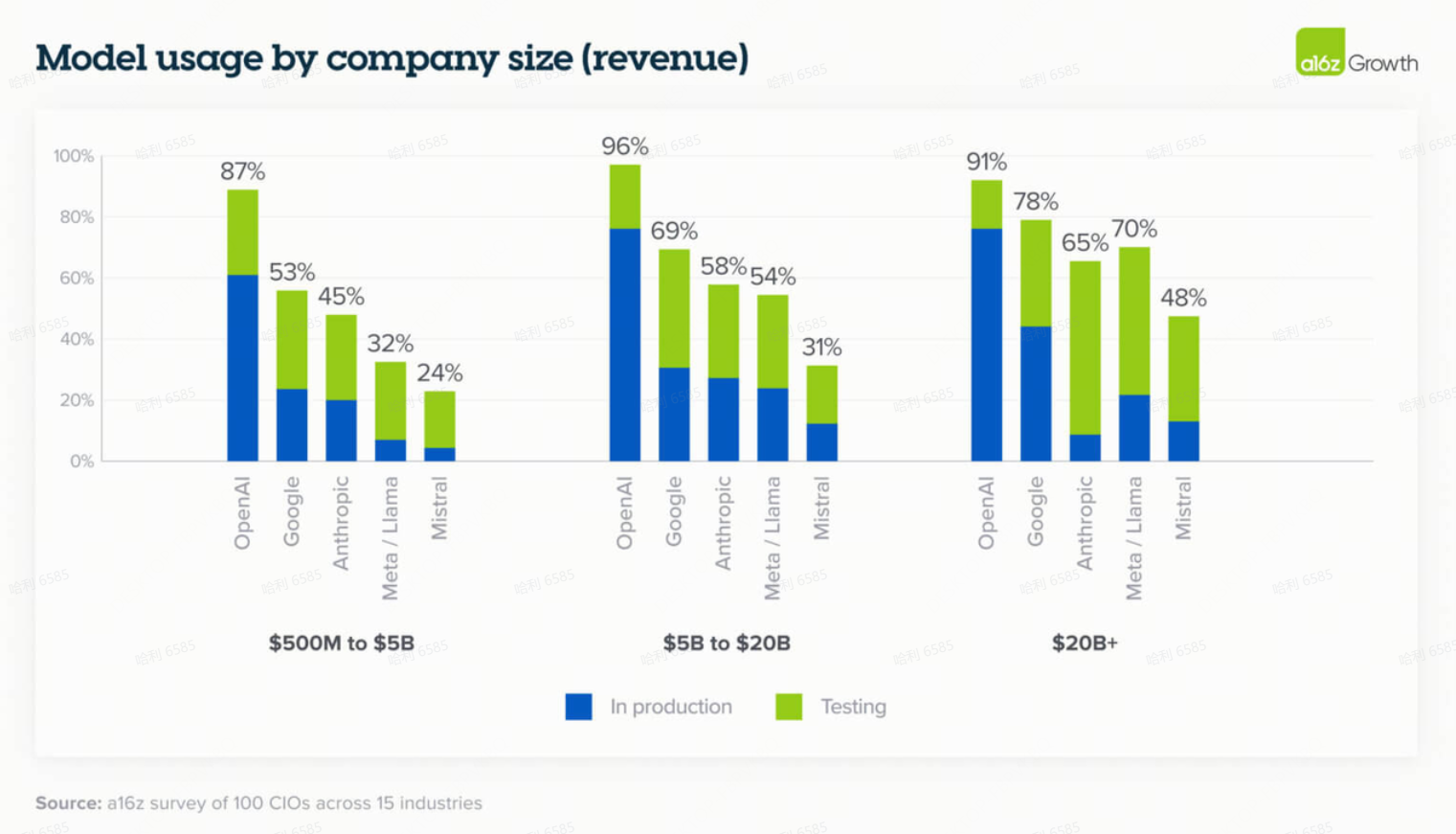
4. 模型领域竞争激烈但清晰的领导者正在浮现
虽然企业继续在实验和生产用例中使用不同的模型,但少数公司在总体采用率上领先:OpenAI 保持了总体市场份额的领导地位,而 Google 和 Anthropic 在过去一年中取得了长足进步。市场份额因企业规模而略有不同,开源采用率更高的情况发生在规模较大的企业中,这些企业仍然主要考虑本地部署(on-prem)。
进一步深入观察使用情况:
- 企业使用 OpenAI 的广泛系列模型。GPT-4o 是部署到生产环境中最多的模型,而 OpenAI o3(推理模型)随着推理模型更多地集成到生产用例中。OpenAI 的非前沿模型(non-frontier models)的采用率远高于其他供应商,因此 Google 和 Anthropic 是靠其前沿模型(frontier models)——Gemini 2.5 及更高版本和 Claude Sonnet 3.5 及更高版本——打开了市场。具体来说,67% 的 OpenAI 用户在生产中部署了非前沿模型,而 Google 只有 41%,Anthropic 只有 27%。
- Google 的崛起在大型企业中更为显著,因为它们经常与 GCP(Google Cloud Platform)有现有关系,并且可以利用这家巨头的品牌信任。Gemini 模型长期以来一直吹捧拥有同类最佳的上下文窗口(context windows),但Gemini 2.5 的整体性能将其推入了真正的前沿模型地位。同样变得明显的是——并可能给Google带来持久力——是Google 的性能成本比。在一个具有可比智能的模型示例中,Gemini 2.5 Flash 的成本为每百万 tokens 26 美分,而 GPT-4.1 mini 的成本为 70 美分。
- Anthropic 在最具技术前瞻性的公司中采用率最高,特别是软件公司和初创公司。他们的模型在某些用例中表现出色,最显著的是代码,并因此为增长最快的 AI 编码应用程序提供动力。这种用例级别的领导地位在企业中并未被忽视,技术前沿的领导者积极按用例评估性能,并通常为工程和编码选择 Anthropic。这为 Anthropic 的收入带来了好处,并也赋予了它们受更传统大型企业重视的规模和声誉。
- 像 Llama 和 Mistral 这样的开源模型的采用率在大型企业中往往高于在较小公司中的采用率。这通常是由对本地部署解决方案的偏好所驱动的,考虑到数据安全性和合规性,以及为特定企业用例进行微调(fine-tune)的能力。
- 像 xAI 这样的新模型提供商开局就获得了强烈的兴趣和早期测试——这让人想起去年的行为,并提醒人们模型市场份额仍然是动态变化的。
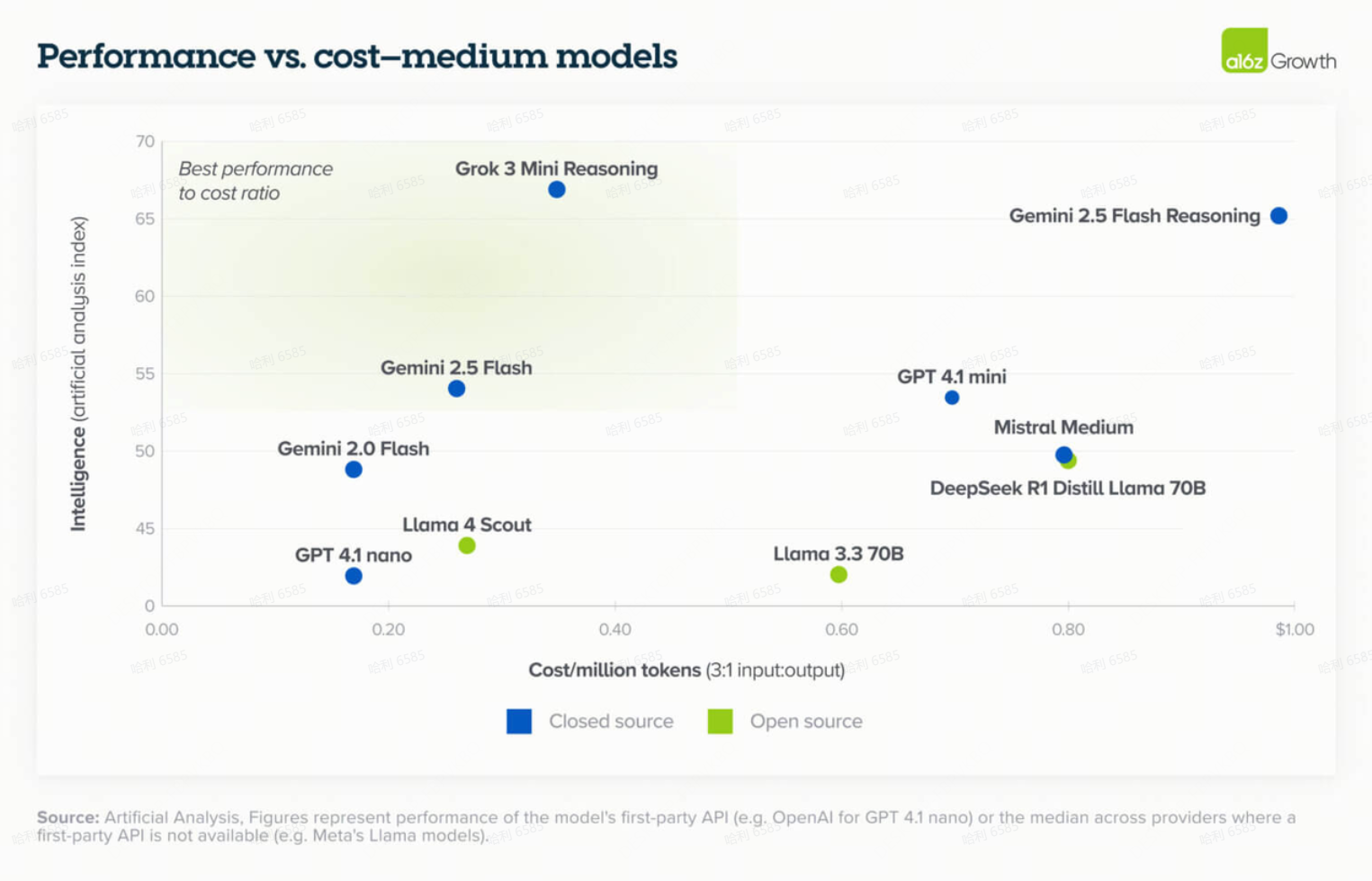
5. 闭源(Closed source)模型的性能价格比对于非前沿模型已变得更具吸引力
模型成本每 12 个月下降一个数量级。在此背景下,我们也看到闭源模型的性能价格比对于中小型模型已变得更具吸引力,xAI 的 Grok 3 mini 和 Google 的 Gemini 2.5 Flash 在这方面领先。在某些情况下,鉴于这种转变以及其他生态系统优势,客户更频繁地选择闭源模型。正如一位客户所说:“定价变得有吸引力了,而且我们已经嵌入了 Google 生态系统:我们从 G Suite 到数据库都在使用,他们的企业专业知识很有吸引力。”或者另一位更简洁地表示:“Gemini 很便宜。”
6. 随着模型能力提升,微调(Fine-tuning)被视为不那么必要
模型能力的改进——主要是更高的智能和更长的背景窗口——使得微调对于实现特定用例的强大模型性能不再那么关键。相反,公司发现提示词工程(prompt engineering)可以驱动类似或更好的结果,而且通常成本低得多。正如一家企业所观察到的:“你不是获取训练数据并进行参数高效的微调,而是直接将其放入长上下文中,就能得到几乎等效的结果。”
这种远离微调的转变也有助于公司避免“模型锁定”,因为微调模型需要高昂的前期成本和工程工作,而提示可以更容易地从一个模型移植到另一个模型。在一个模型快速改进、公司希望保持在领先优势的世界里,这一点很重要。
也就是说,具有超特定用例的公司仍然在对模型进行微调。例如,一家流媒体服务对开源模型进行微调,用于视频搜索中的查询增强,“在那里你需要更多的领域适应性(domain adaptation)”。如果更新的方法(如强化微调 reinforcement fine tuning)在实验室之外得到更广泛的采用,我们可能也会看到微调的增加。
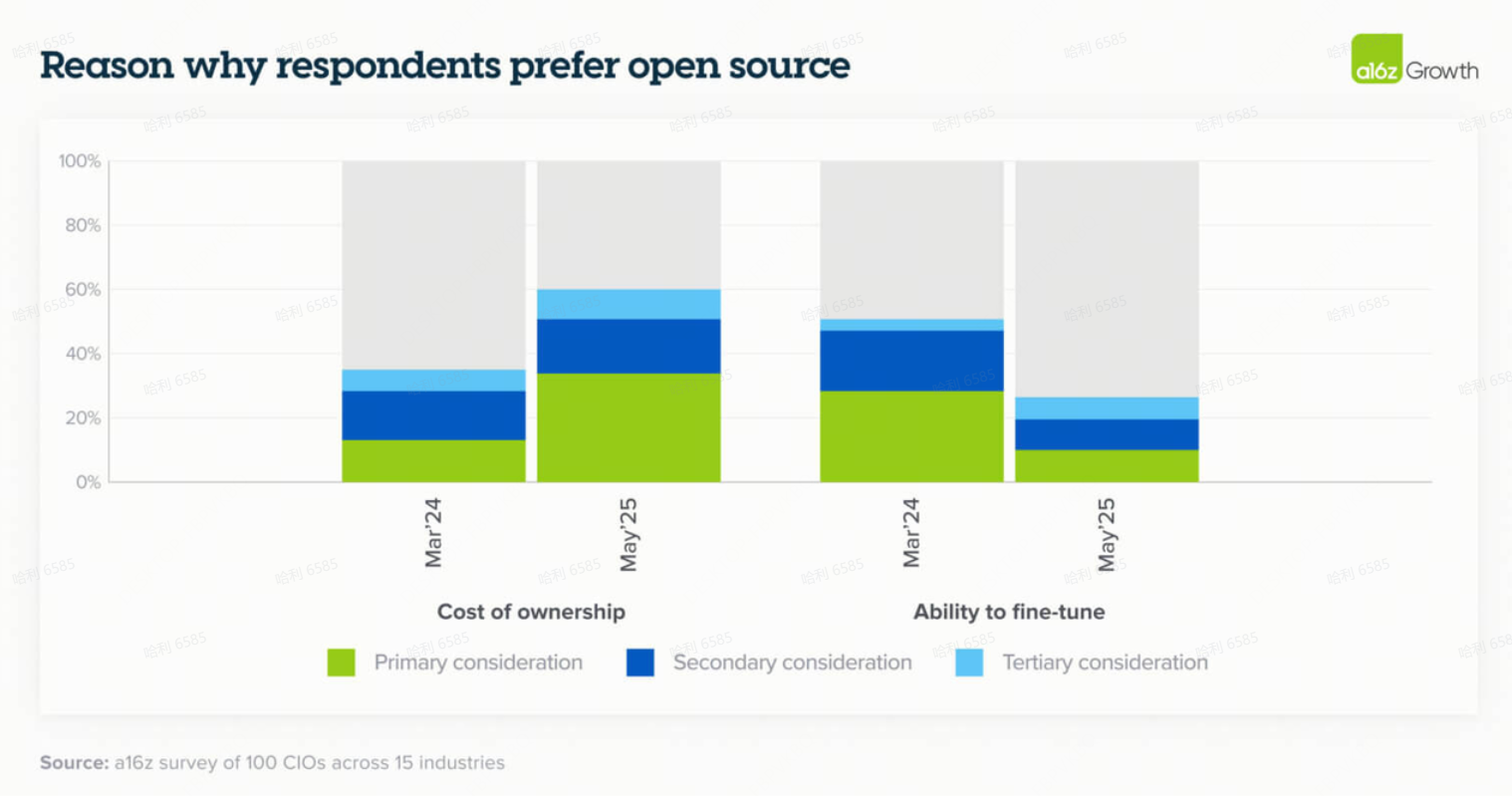
随着模型能力的提高,大多数企业不像去年那样看到微调的投资回报率(ROI),并且主要出于对成本高度敏感的用例而选择开源模型。
7. 企业对推理模型(Reasoning models)持乐观态度并准备快速扩展
通过让 LLM 更准确地完成更复杂的任务,推理模型扩展了 LLM 可以处理的用例范围。企业仍处于推理模型测试的早期阶段,很少有企业将其部署到生产环境中,但公司对其潜力非常乐观。我们采访的一位高管很好地抓住了这一点:“推理模型允许我们解决更新、更复杂的用例,因此我预计我们的使用量会大幅跃升。但我们仍处于早期阶段,目前仍在测试。”
在早期采用者中,OpenAI 的推理模型获得了最大的关注度。尽管围绕 DeepSeek 有大量的关注,但企业绝大多数采用 OpenAI,23% 的受访企业已经在生产中使用 OpenAI 的 o3 模型,而 DeepSeek 只有 3%。DeepSeek在初创公司中的采用率相对于其在企业中的低接受度要高一些。
# 03
采购:企业AI采购采用传统软件采购的严谨性
8. 模型的购买过程越来越类似于传统的企业软件采购,包括检查清单和价格敏感度
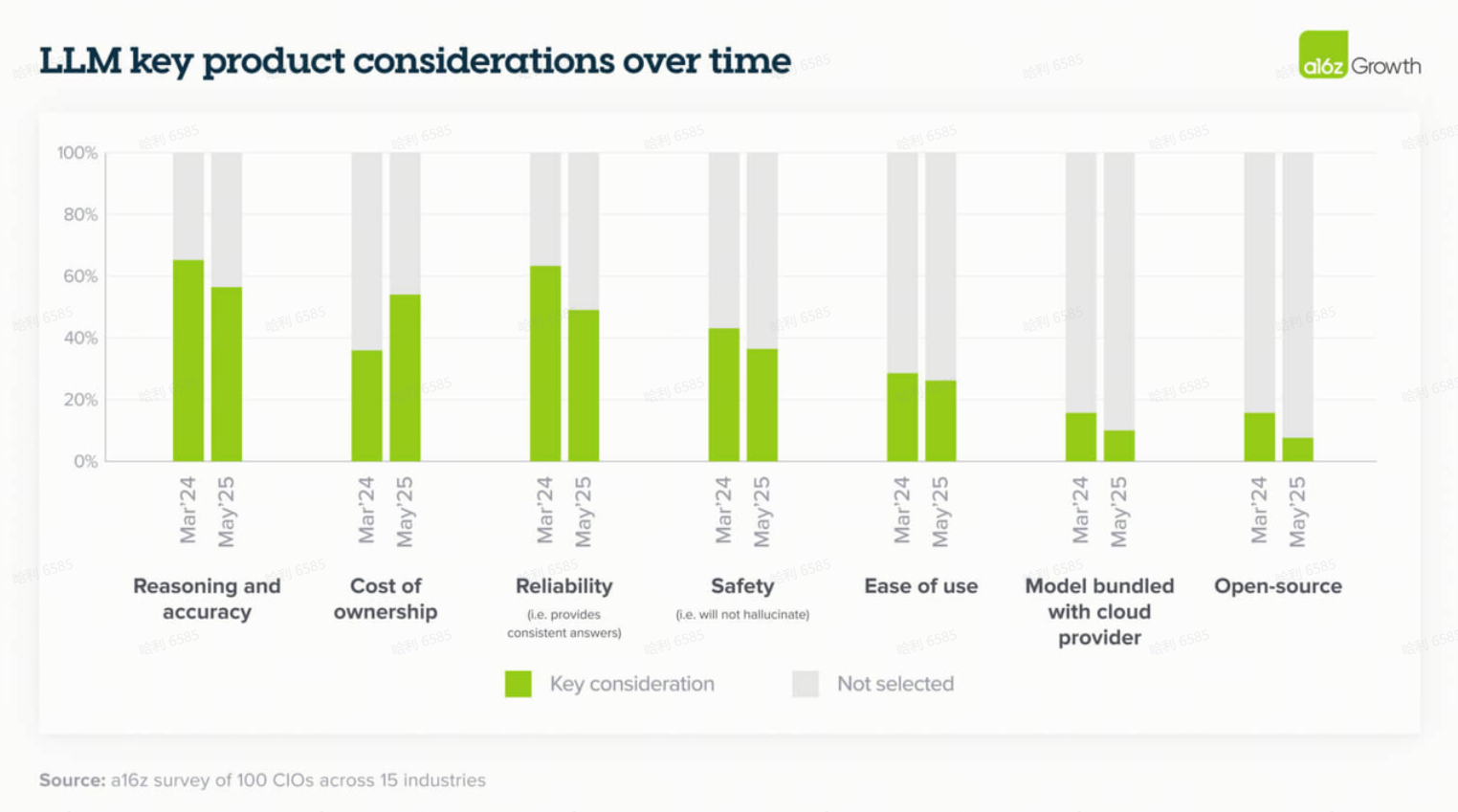
公司现在以规范的评估框架来处理模型选择,并且诸如安全性(在我们的访谈中被高度重视)和成本等因素在整体准确性和可靠性方面获得了更多重视。这种转变强调了企业对模型性能的信任度增加,以及 LLM 将被大规模部署的信心。正如一位领导者简明地总结道:“对于大多数任务,所有模型现在都表现得足够好——所以定价已成为一个更重要的因素。”
正如我们在“模型”部分提到的,企业也在将特定用例与合适的模型匹配方面变得更加成熟。对于高度可见或性能关键的应用,公司通常更喜欢具有强大品牌认知度的前沿模型。相反,对于更简单或内部的任务,模型选择通常纯粹取决于成本。
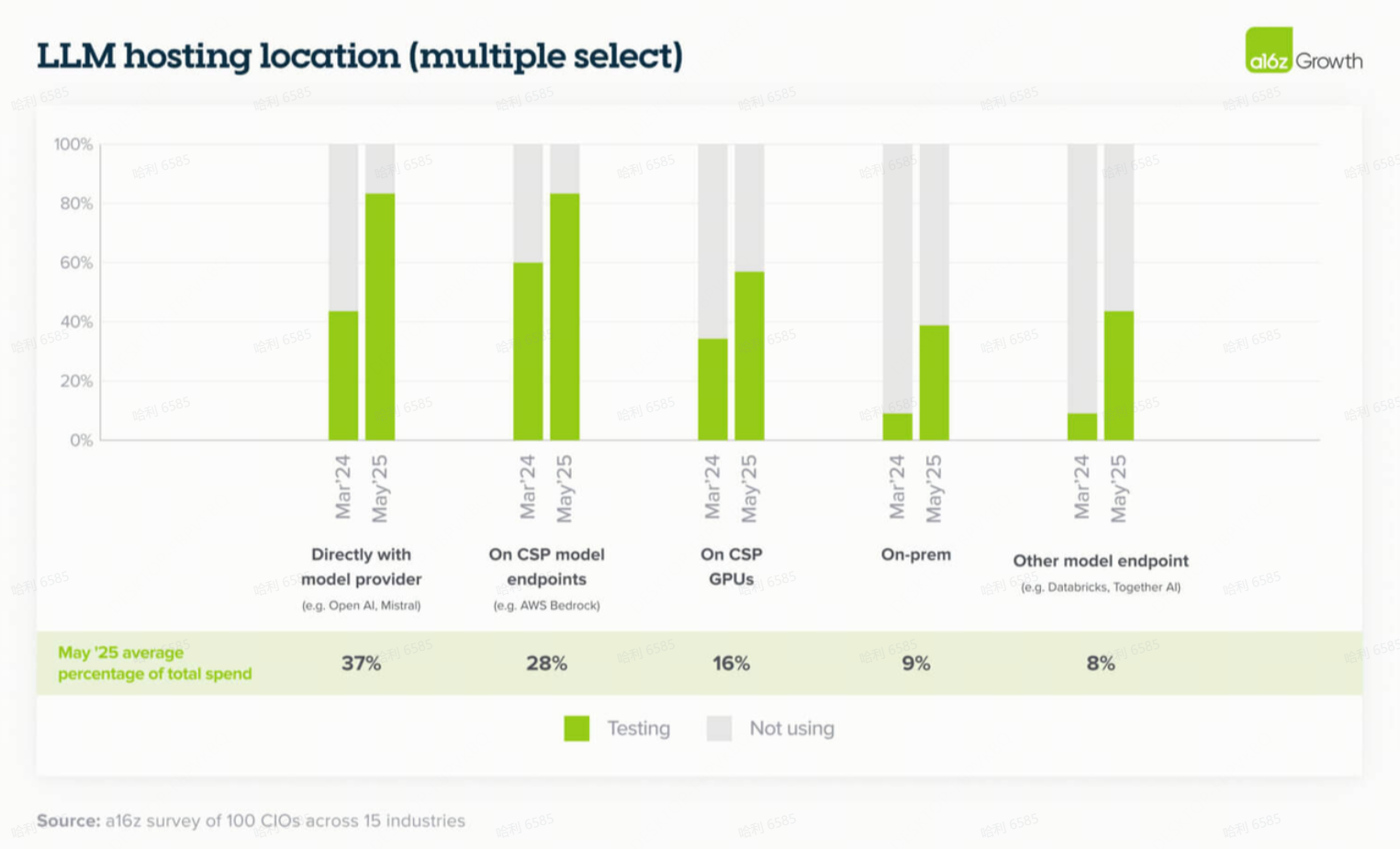
9. 托管偏好仍然差异很大,尽管企业在过去一年中迅速建立了对模型提供商的信任
虽然仍然存在对现有云关系(类似于其他基础设施采购)的一些偏好,但更多的企业正在直接通过模型提供商或通过 Databricks 进行托管,特别是在选择的模型未由其主要云提供商托管的情况下(例如,AWS 客户使用 OpenAI )。
这通常是因为领导者“希望直接访问具有最佳性能的最新模型,早期访问预览也很重要。”与模型提供商(包括 OpenAI 和 Anthropic)直接合作的信任度增加,与我们去年与企业访谈时听到的情况相比是一个重大转变:当时许多企业尽可能通过云提供商访问模型,有时甚至不是通过其主要云提供商。
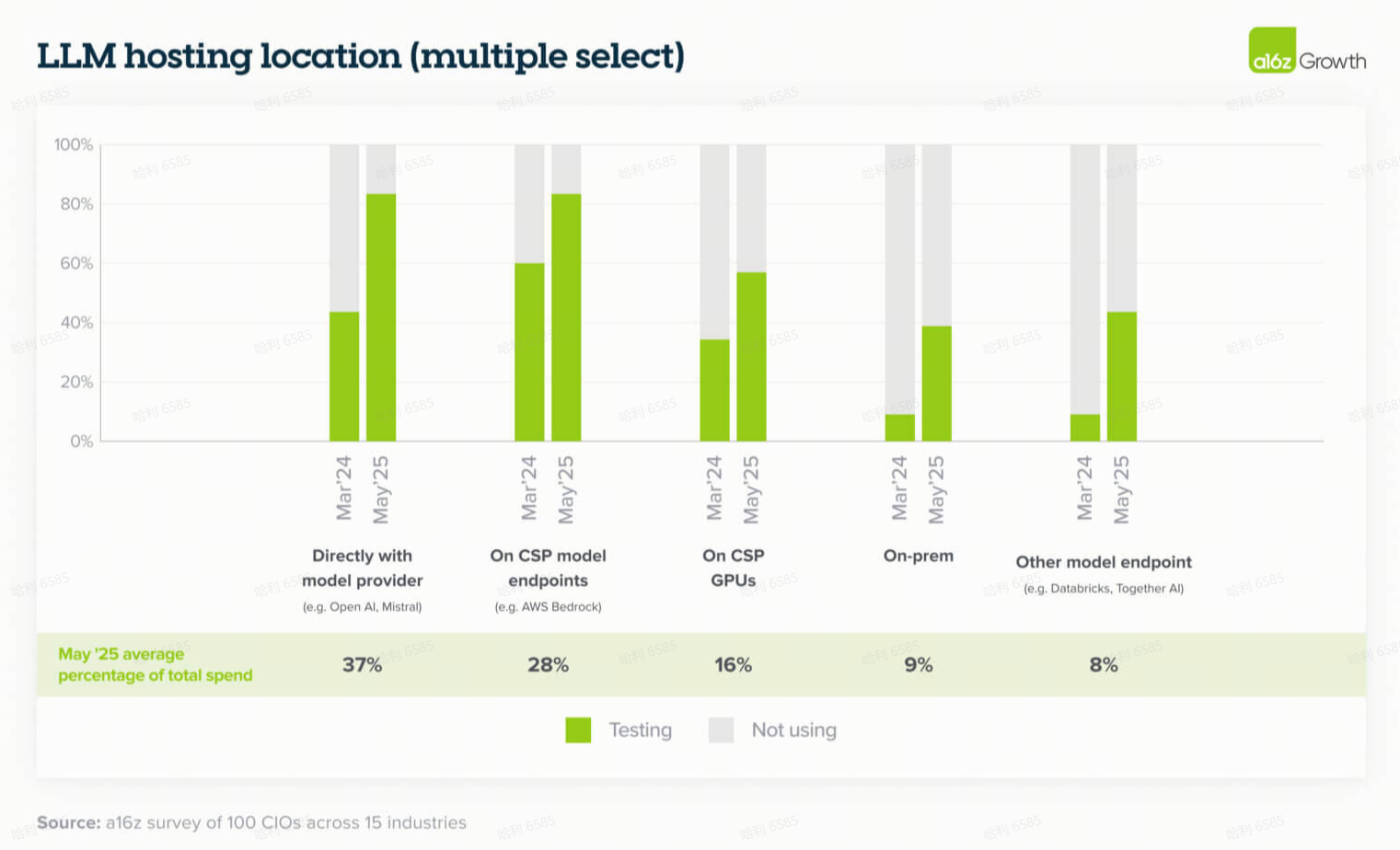
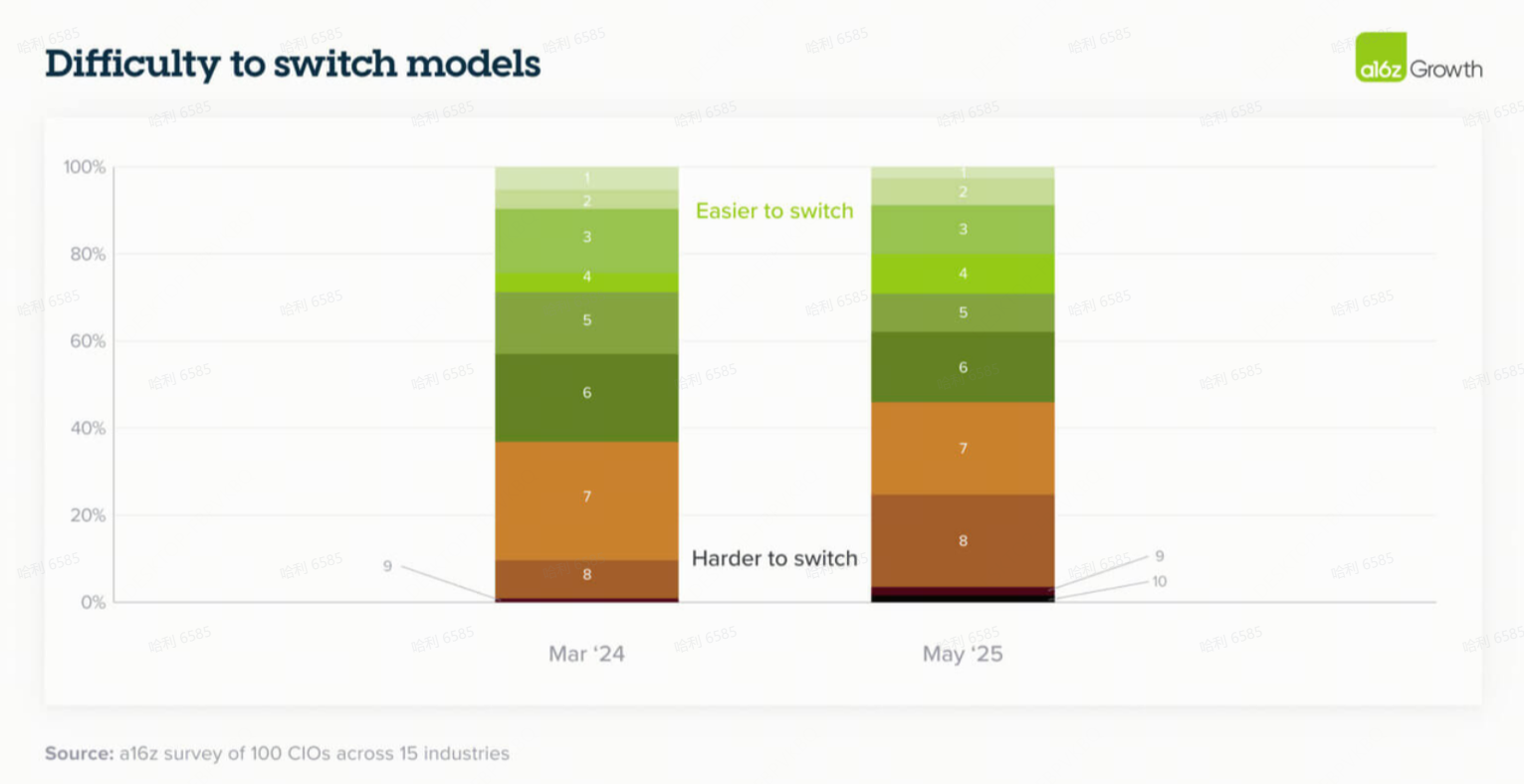
10. 随着AI处理更复杂的任务,转换成本正在上升
去年,我们发现大多数企业正在设计其应用程序以最小化转换成本,并使模型尽可能可互换。因此,许多企业将模型视为“来得容易,去得也容易”(easy come, easy go)。这对于简单的、一次性的(one-shot)用例可能很有效,但智能体工作流程(agentic workflows)的兴起开始使得在模型之间切换变得更加困难。
随着公司投入时间和资源为智能体工作流程构建防护栏(guardrails)和提示(prompting),如果结果无法复制或者需要投入大量时间来设计不同模型的可靠性,他们更不愿意切换到其他模型。智能体工作流程通常需要多个步骤来完成一项任务,因此更改模型工作流程的一个部分可能会影响所有下游依赖项。正如一位领导者告诉我们:“所有提示都是为 OpenAI 调整的。每一个都有自己的一套指令、提示和细节。LLM 如何获得指令来处理智能体过程——需要很多页的指令。而且,智能体的质量保证并不超级容易,所以更换模型现在是一项可能花费大量工程时间的任务。”
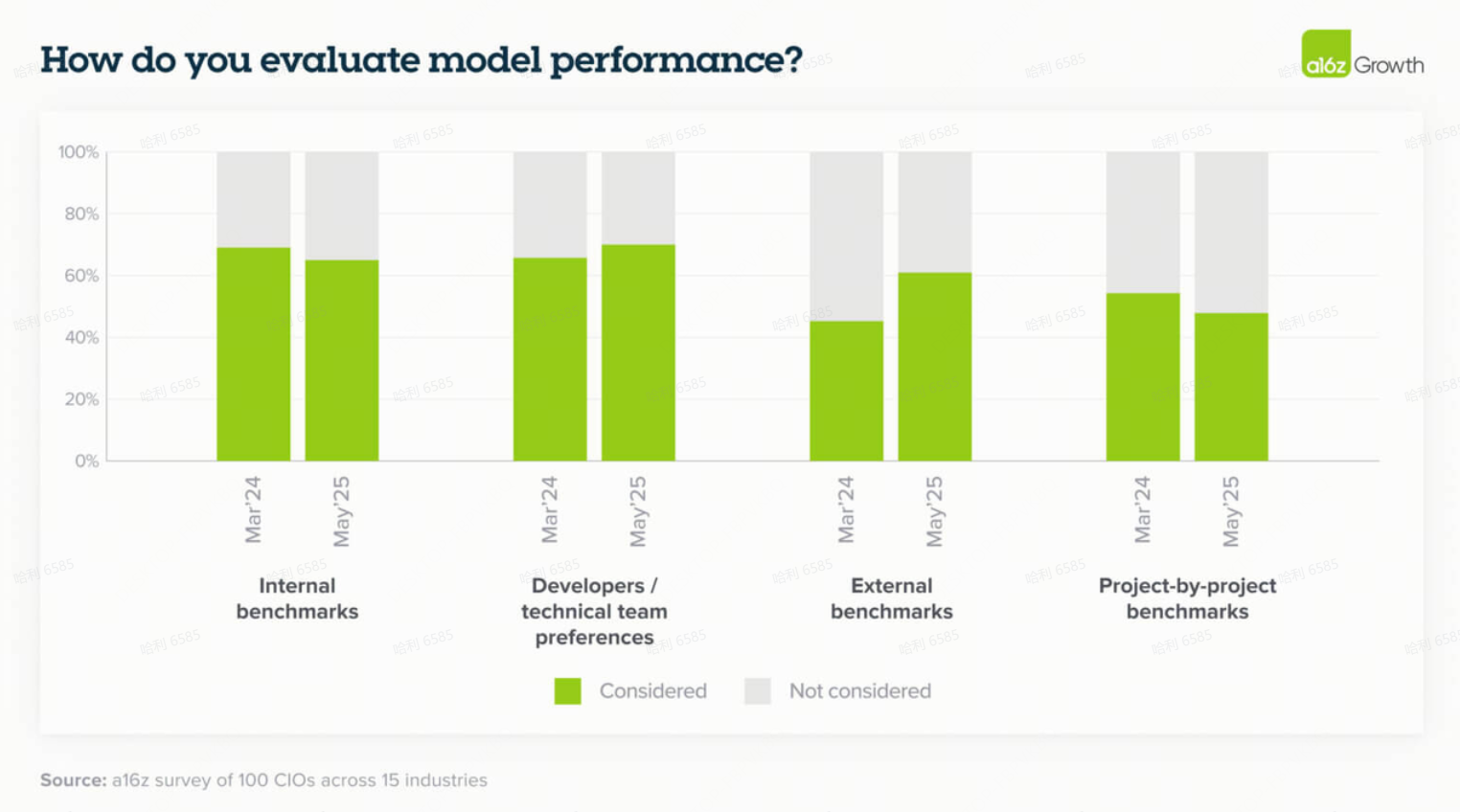
11. 企业越来越多地参考外部基准作为准“魔力象限”(Magic Quadrants),作为模型选择的初始过滤器
随着模型的激增,外部评估提供了一种实用的、类似 Gartner 的过滤器,这是企业从其传统软件采购过程中所熟悉的。
虽然内部基准、黄金数据集(golden datasets)和开发者反馈仍然是更深入评估 LLM 性能的关键部分,但 LLM 市场的成熟已推动公司越来越多地参考外部基准,如 LM Arena。尽管这些外部基准有助于企业买家筛选市场,但领导者也指出,这些基准只是更广泛评估过程中的一个因素:“我们肯定会看外部基准。但你仍然需要自己评估。不真正试用并获得员工反馈,很难做出选择。”
# 04
应用的兴起:AI应用增长迅猛,因更多企业决定跨更多用例购买而非构建
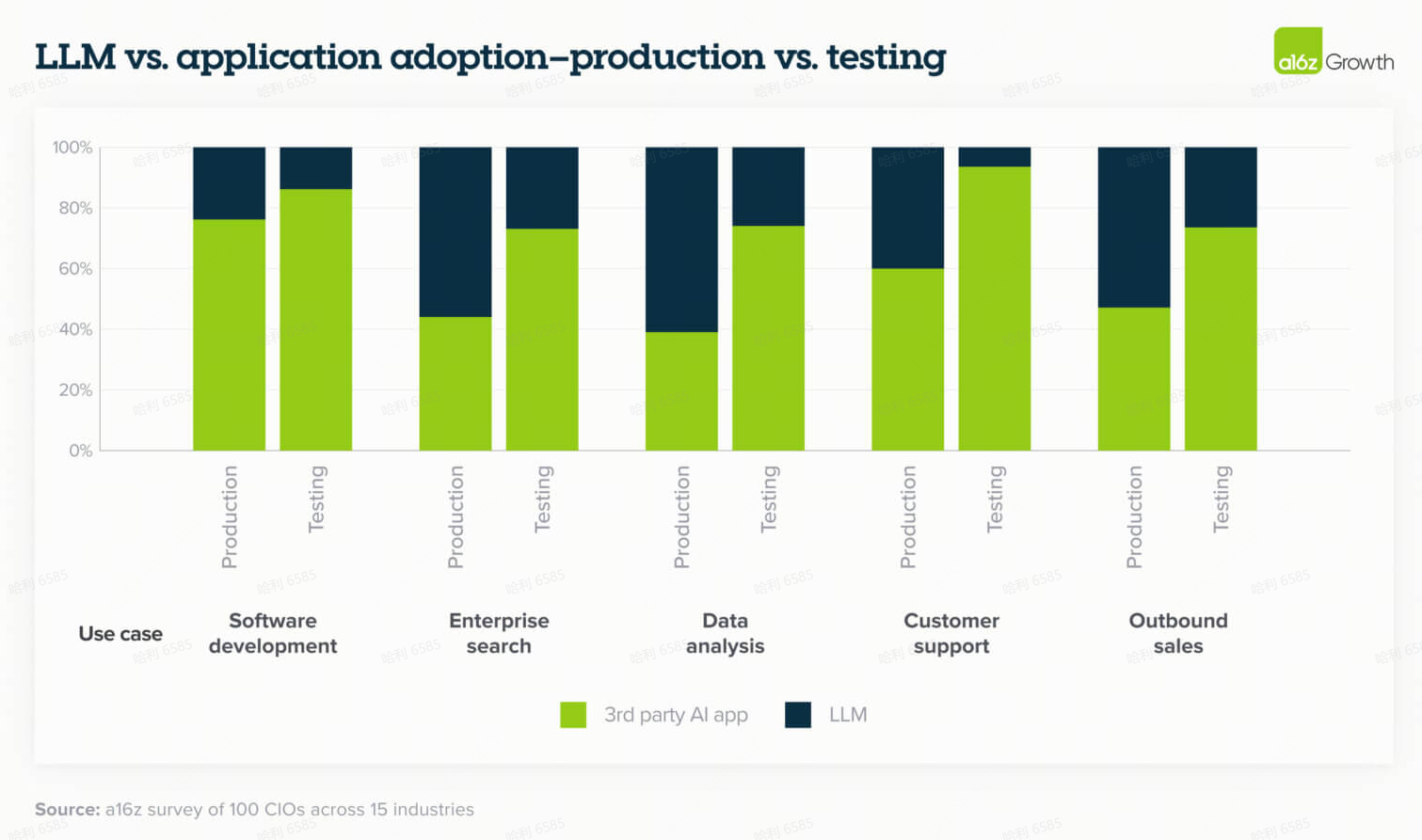
12. 随着AI应用生态系统的形成,企业正从“构建”转向“购买”
在 AI 产品周期的早期,企业大多选择直接与 AI 模型合作并构建自己的应用程序。然而,在过去十二个月中,随着 AI 应用生态系统的开始成熟,我们看到了向购买第三方应用程序的显著转变。特别是,由于跨模型的动态性能和成本差异化导致了通过按用例持续评估和优化来实现增量 ROI 收益,这通常最好由专门的 AI 应用团队而不是内部团队来处理。
此外,在像 AI 这样动态的领域,公司发现内部开发的工具难以维护,并且通常不会给它们带来业务优势——这进一步巩固了它们购买而非构建应用程序的兴趣。
随着更多应用类别的成熟,我们预计这一趋势在未来将更倾向于第三方应用程序,领导者们在测试新用例时更重视应用程序这一领先指标就证明了这一点。例如,在客户支持方面,超过 90% 的受访者指出他们正在测试第三方应用程序。一家上市金融科技公司指出,虽然他们开始内部构建客户支持,但最近对市场上第三方解决方案的审查说服了他们购买,而不是继续构建。我们尚未看到这一趋势发挥作用的领域是受监管或高风险行业,如医疗保健,那里数据隐私和合规性更受关注。
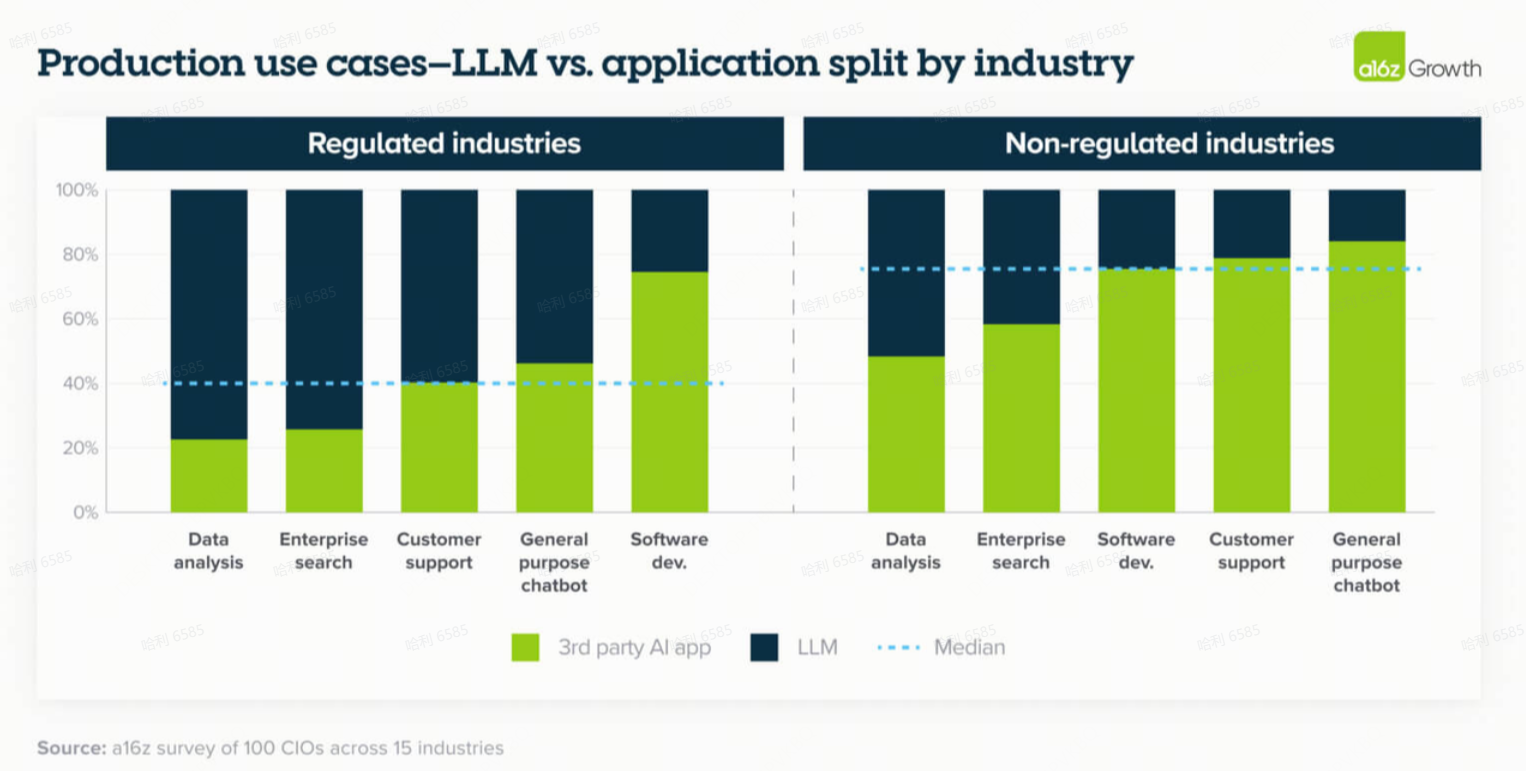
13. 买家对应用程序的基于结果定价(Outcome-based pricing)感到挣扎
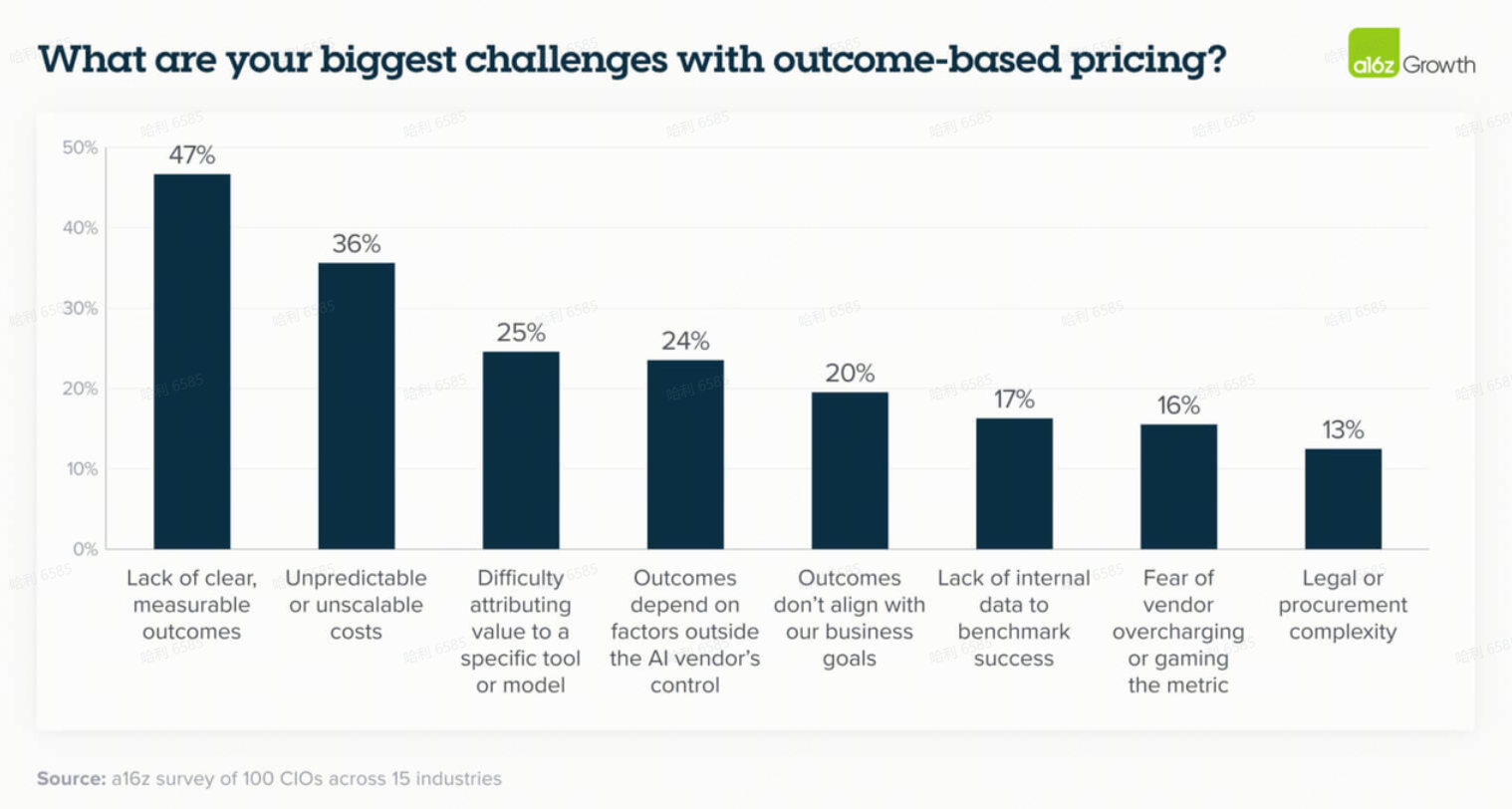
虽然围绕 AI 的基于结果定价有很多炒作,但 CIO 们仍然对结果指标如何设定、衡量和计费感到不安。
基于结果定价的一些主要担忧是缺乏与业务目标相关的明确结果、不可预测的成本和归因(attribution)问题——但在供应商如何缓解这些问题方面没有共识。这并不奇怪,因为 AI 是一项相对较新的技术,如何实施它以真正为企业带来价值尚不清楚。买家不知道他们会被收取多少费用,并且不想最终独自承担损失。鉴于此,大多数 CIO 仍然倾向于为 AI 应用程序按使用量付费。
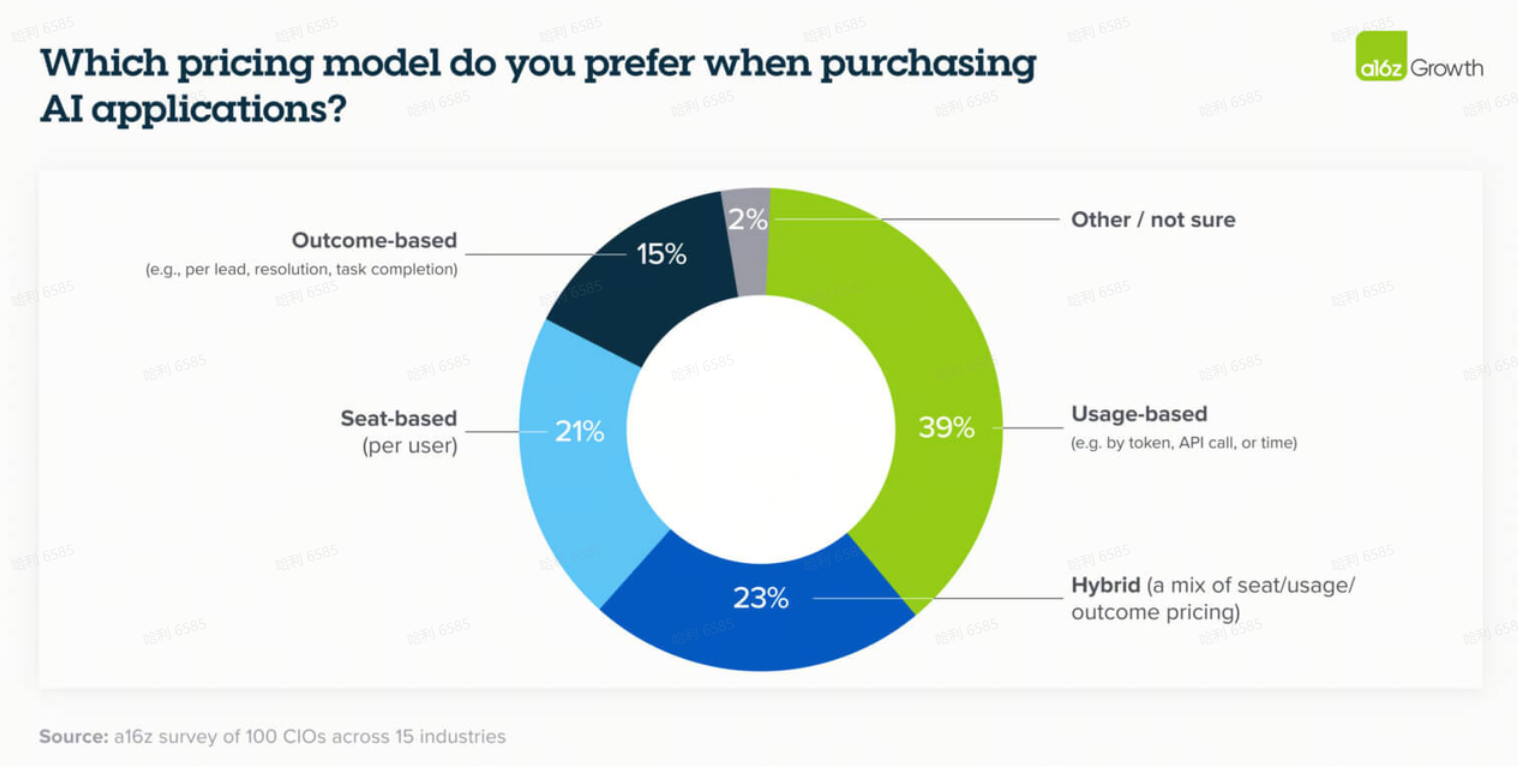
14. 软件开发成为杀手级用例(Killer use case)——其他用例紧随其后
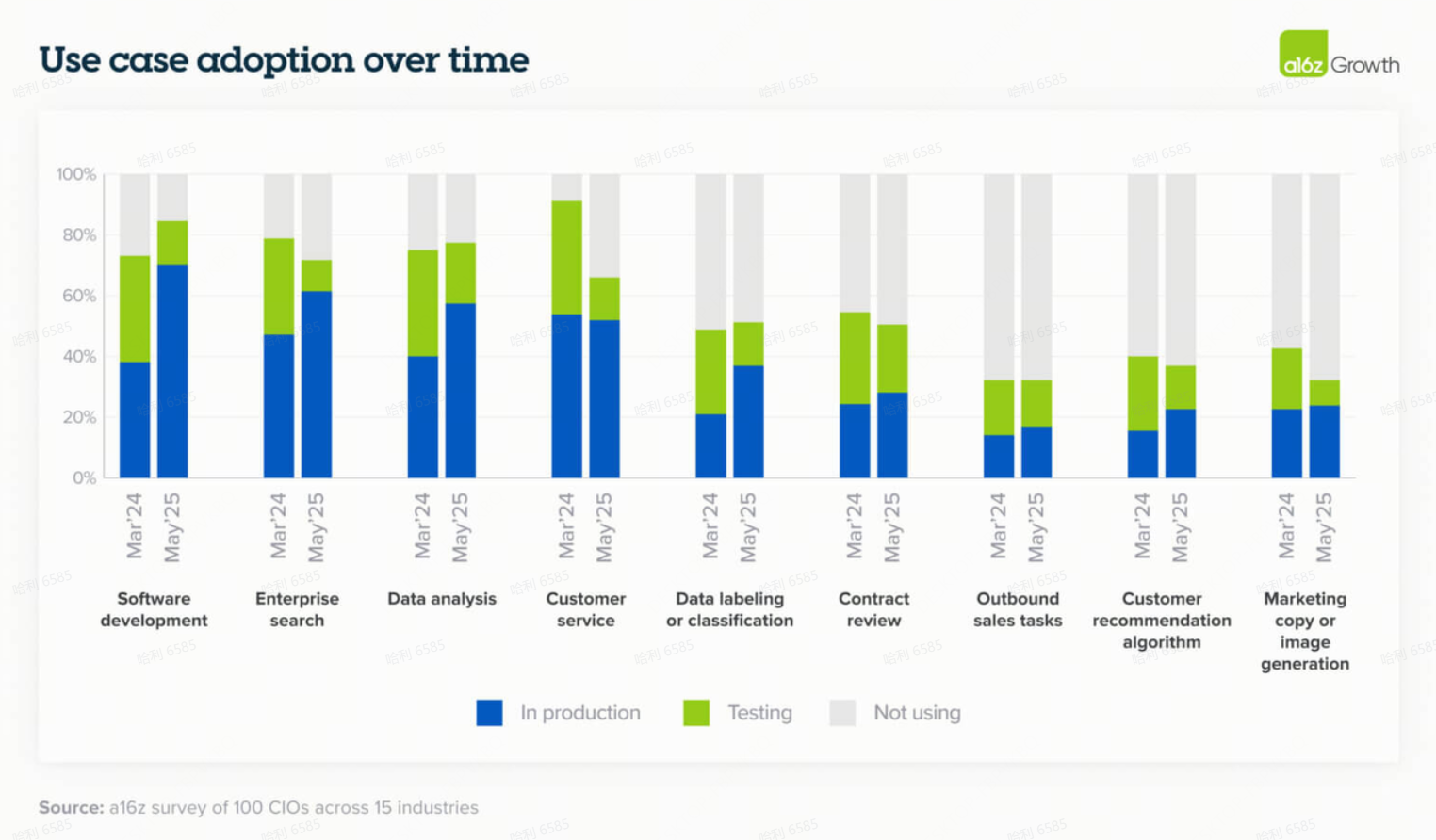
虽然我们看到 AI 用例在各个领域逐步被采用——特别是内部企业搜索、数据分析和客户支持——但软件开发的采用出现了阶跃变化(step change),这是由一系列因素共同驱动的完美风暴:极其高质量的现成应用程序、模型能力的显著提高、对广泛公司和行业的普适性,以及一个毋庸置疑的 ROI 用例。
一家高增长 SaaS 公司的 CTO 报告称,他们近 90% 的代码现在是通过 Cursor 和 Claude Code 的 AI 生成的,而12个月前使用 GitHub Copilot 时这一比例仅为 10-15%。这种采用水平仍然代表着前沿,但很可能成为企业的一个强有力的领先指标。
15. 专业消费者市场(Prosumer market)推动了早期应用增长的很大一部分并影响了企业购买行为
强大的消费者品牌正在转化为强大的企业需求。
就像一些早期的平台转变(例如互联网)一样,领先的企业 AI 应用的早期增长很大一部分是由专业消费者市场(介于专业和消费者之间)推动的。这由 ChatGPT 启动,并得到编码应用程序和像 ElevenLabs 这样的创作者工具的强调。许多 CIO 指出,他们购买企业版 ChatGPT 的决定是受“员工喜爱 ChatGPT。这是他们知道的品牌名称”所驱动。这种双重市场拉动导致新一代 AI 公司的增长速度比我们过去看到的要快得多。
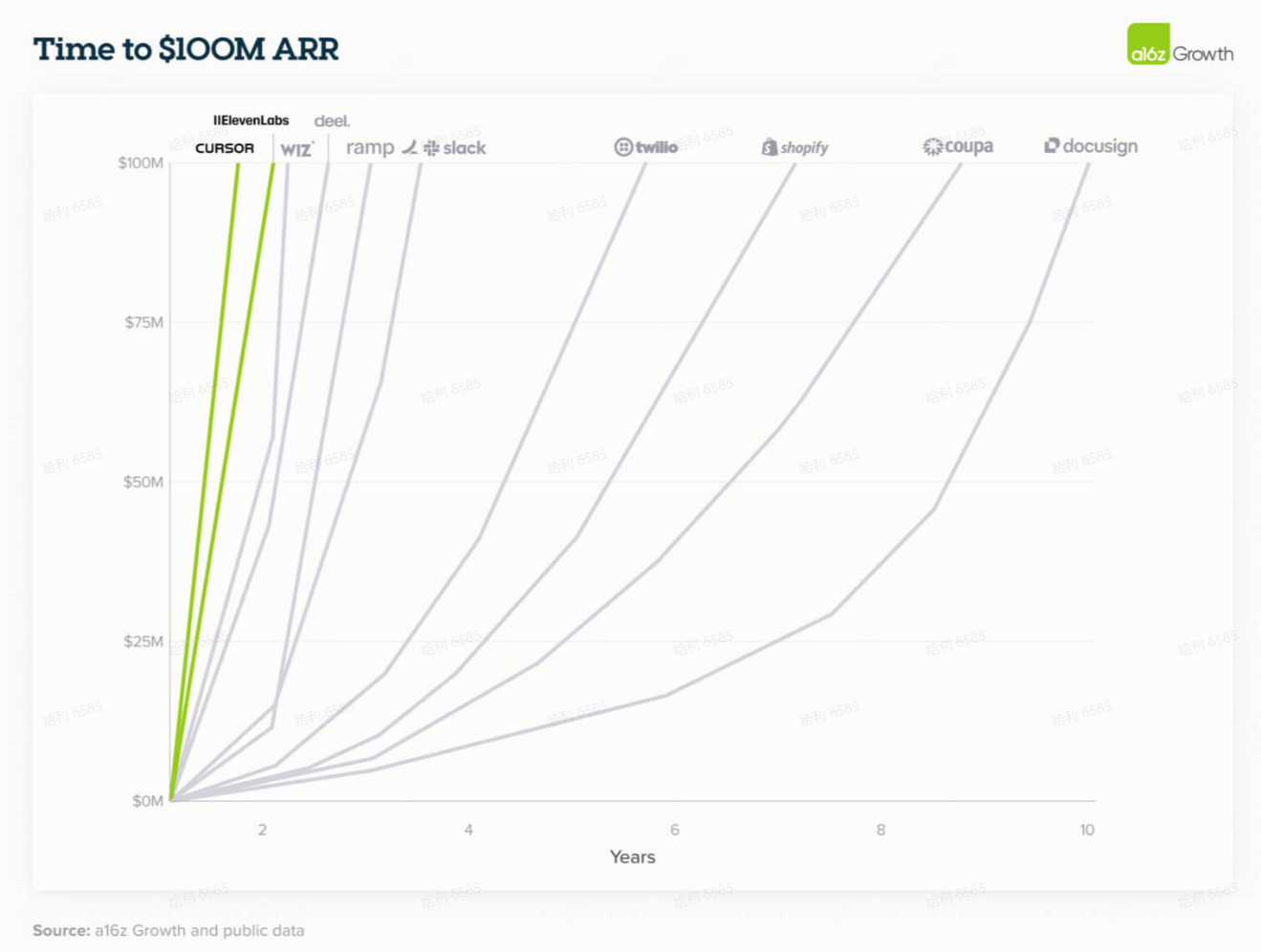
16. AI原生产品(AI-native)的质量和速度开始超越现有企业(Incumbents)
现有企业一直受益于既有的信任和现有的分销渠道,但在 AI 时代,它们在产品质量和创新速度方面越来越被 AI 原生的竞争对手所超越。
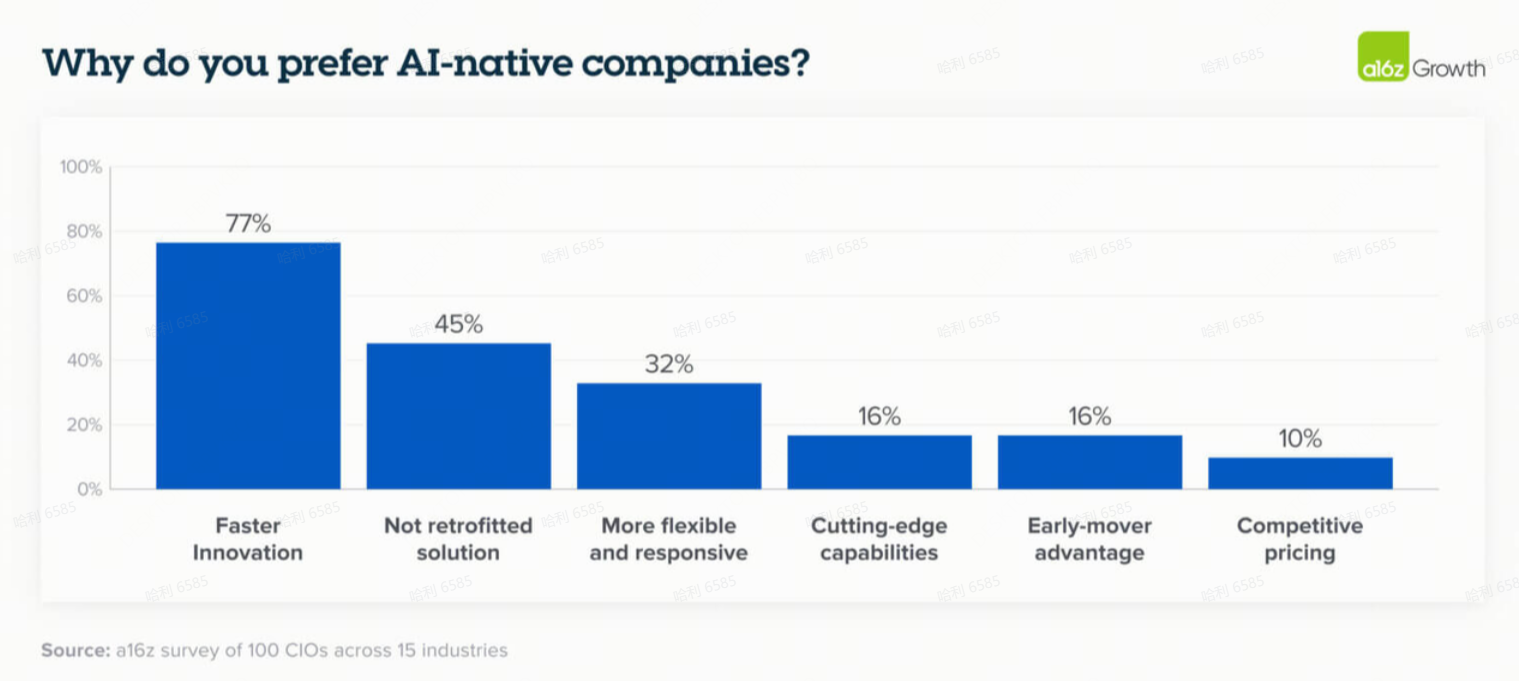
毫不奇怪,买家偏好 AI 原生供应商的主要原因是它们更快的创新速度。第二个原因是认识到,相比于现有企业将 AI 改造到现有解决方案中,围绕 AI 从头构建的公司能提供根本上更好的产品和卓越的结果。
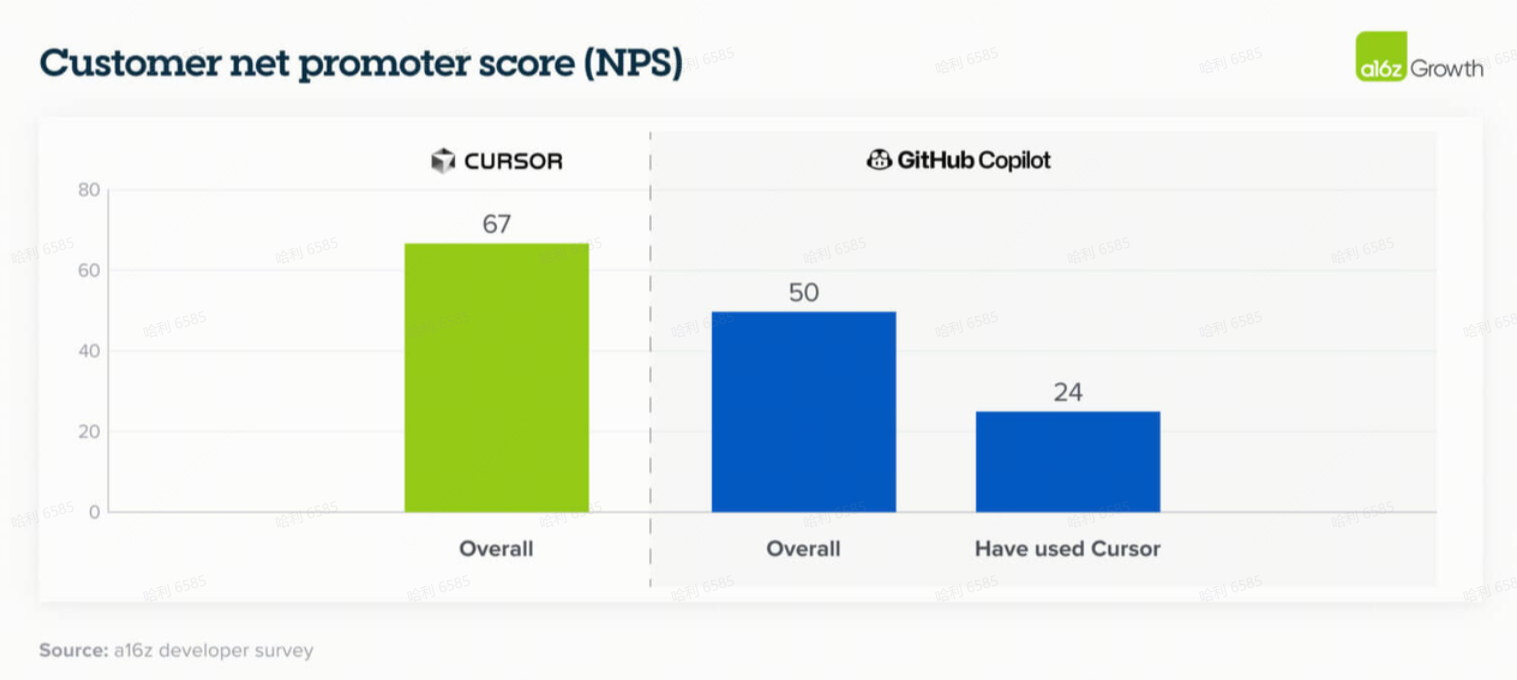
这种差距今天在软件开发中尤其明显,一家上市安全公司的 CIO 强调了第一代和第二代 AI 编码工具在编码变得更加智能体化(agentic)时的能力差异。用户满意度数据也呼应了这种转变:采用 Cursor(一种生成式AI原生编码解决方案)的用户对上一代工具(如 GitHub Copilot )的满意度明显较低,这强调了创新如何迅速从根本上重塑买家对 AI 可以且应该期望的结果。
# 05 展望未来
企业 AI 领域不再由实验来定义:它由战略部署、预算承诺和成熟的供应商生态系统所塑造。随着模型选择的多样化,按用例的碎片化不仅是预期的,而且是被接受的,并且少数关键领导者正在浮现。企业正在采用结构化的采购流程,并越来越多地转向现成的应用程序以加速采用。其结果是一个看起来更像传统软件的市场——却又以 AI 独有的速度和复杂性在发展。
最后,我们已将本文中涉及的 20 张图表整理为 PDF ,可扫下方二维码或点击阅读原文下载;此外,本文提及的模型主要为海外 AI 市场的前沿闭源模型,而此前 PPIO 曾发布过 2025 上半年国内市场大模型 tokens 消耗报告,也可扫码下载后对比相关信息。
